/*
----------------------------------------------------------------
Copyright (C) California Institute of Technology. All
rights reserved. US Government Sponsorship is acknowledged.
----------------------------------------------------------------
*/
/**
\file summary_wsdb.c
\author This file was generated by the
WAX source generation utility
\date Wed Sep 8 22:43:44 2004
*/
#include <math.h>
#include "common.h"
#include "vector.h"
#include "appgroup.h"
#include "info_example.h"
#include "putil.h"
#include "summary.h"
static double sgSinRad;
/* Allocates resources for group/apparition processing */
void initProcess(const double rad,
const double decmin,
const double decmax)
{
/* Precompute the sine of the grouping radius. */
sgSinRad = sin( gRadPerDeg * (rad / 3600.0) );
/* Load the BSP files for the band being processed. */
loadBsp(decmin, decmax, TRUE);
}
/* Releases resources allocated for group/apparition processing */
void freeProcess()
{
/* Nothing to do here */
}
/* Processes a group containing at least two apparitions */
int processGroup(Group * const grp,
const size_t napp,
const App * const * const list)
{
Vec3 avgpos;
RaDec avgloc;
GroupInfo * ginfo;
const App * const * a;
const App * const * alim;
const App * app;
/* Get a pointer to the GroupInfo structure
to store computed attributes in */
ginfo = grp->info;
/* Set the initial average position to the zero vector */
avgpos.x = 0;
avgpos.y = 0;
avgpos.z = 0;
/* Loop over all apparitions in the group, adding the
vector position of each one to avgpos */
a = list;
alim = list + napp;
while (a < alim)
{
app = *a;
++a;
vadd2(&avgpos, &(app->pos));
}
/* normalize the sum of all the apparition positions,
obtaining an average position for the group */
vnormalize(&avgpos);
/* convert the average position vector to a right ascension
and declination */
vtord(&avgloc, &avgpos);
/* store the average position in the GroupInfo structure */
ginfo->ra = avgloc.ra;
ginfo->dec = avgloc.dec;
ginfo->x = avgpos.x;
ginfo->y = avgpos.y;
ginfo->z = avgpos.z;
/* Compute the HTM index for the groups average position */
getSpatialIndex( &avgpos, &(ginfo->spt_ind) );
/* Compute the minimum and maximum scan coverage for a circular
region centered on the groups average position with a radius
equal to the group radius. */
overlapRange(
&avgloc,
&avgpos,
sgSinRad,
&(ginfo->smin),
&(ginfo->smax)
);
/* Compute scan coverage for the groups average position */
overlapRange(
&avgloc,
&avgpos,
0.0,
&(ginfo->spos),
&(ginfo->spos)
);
/* return the GROUP_OK constant to indicate that this group
should be inserted into the output tables */
return GROUP_OK;
}
/* Processes a group containing a single apparition */
int processSingle(Group * const grp,
const App * const app)
{
GroupInfo * ginfo;
/* Get a pointer to the GroupInfo structure
to store computed attributes in */
ginfo = grp->info;
/* The average group position is identical
to the apparition position */
ginfo->ra = (app->loc).ra;
ginfo->dec = (app->loc).dec;
ginfo->x = (app->pos).x;
ginfo->y = (app->pos).y;
ginfo->z = (app->pos).z;
/* Compute the HTM index for the groups average position */
getSpatialIndex( &(app->pos), &(ginfo->spt_ind) );
/* Compute the minimum and maximum scan coverage for a circular
region centered on the groups average position with a radius
equal to the group radius. */
overlapRange(
&(app->loc),
&(app->pos),
sgSinRad,
&(ginfo->smin),
&(ginfo->smax)
);
/* Compute scan coverage for the groups average position */
overlapRange(
&(app->loc),
&(app->pos),
0.0,
&(ginfo->spos),
&(ginfo->spos)
);
/* return the GROUP_OK constant to indicate that this group
should be inserted into the output tables */
return GROUP_OK;
}
/* Processes an apparition */
void processApparition(const App * const app,
GroupedAppInfo * const gainfo,
const size_t ngrp,
const Group * const * const list)
{
double dp, maxdp;
const Group * const * g;
const Group * const * glim;
const Group * grp;
const Group * best;
const GroupInfo * ginfo;
if (ngrp == 1)
{
/* there is only one choice for the "best" group */
best = *list;
}
else
{
/* Set the maximum dot product to -2 (smaller than
any dot product of two unit vectors) */
maxdp = -2.0;
/* Loop over all groups containing the apparition, finding the
one with average position closest to the apparition */
g = list;
glim = list + ngrp;
while (g < glim)
{
grp = *g;
++g;
ginfo = grp->info;
/* compute the dot-product of the apparition position
and the group average position */
dp = (app->pos).x * (ginfo->x) +
(app->pos).y * (ginfo->y) +
(app->pos).z * (ginfo->z);
/* if this dot product is greater than the previous
maximum dot product, then grp is closer to app than
best, so set best to equal grp */
if (dp > maxdp)
best = grp;
}
}
/* Now the best group is known. Copy its attributes to gainfo */
gainfo->ngrp = ngrp;
gainfo->best_gcntr = best->gcntr;
gainfo->best_napp = best->napp;
gainfo->best_gtype = best->gtype;
gainfo->best_sdet = best->sdet;
ginfo = best->info;
gainfo->best_smin = ginfo->smin;
gainfo->best_smax = ginfo->smax;
gainfo->best_spos = ginfo->spos;
/* all done */
}
/* ---------------------------------------------------------------- */
/* ================================================================ */
|
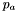
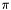 , constants for converting between radians and degrees, etc... Also provides various utility functions, including functions for converting strings to integers and floating point numbers, functions for message logging, and timing functions.
, constants for converting between radians and degrees, etc... Also provides various utility functions, including functions for converting strings to integers and floating point numbers, functions for message logging, and timing functions. 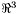 ) structures, as well as functions operating on them. These include functions for computing the vector cross and inner products, functions for vector normalization and magnitude, etc... Note that
) structures, as well as functions operating on them. These include functions for computing the vector cross and inner products, functions for vector normalization and magnitude, etc... Note that 